Jan 22, 2026
Articles
Can We Trust LLMs for Product Compliance?

Martín Ramírez

Note:
This post was inspired by many conversations I have with compliance professionals seeking to leverage AI to become more efficient and reduce risk. That conversation usually ends with me saying a version of:
Can I upload a label to Gemini or any LLM and ask it whether it's compliant? Yes.
Do I trust the results reflect the latest regulatory context, provide nuanced remediation to correct the artwork, and provide traceability in case of an audit? Nope.
I'm clearly biased toward specialized business apps for compliance (since I built one :)).
Here is a bit more depth to my point.
The landscape of product compliance is evolving rapidly, shaped by the increasing complexity of global regulations and the accelerating pace of innovation in artificial intelligence. As organizations strive to bring products to market efficiently while ensuring adherence to a labyrinth of regulatory requirements, the question of leveraging advanced AI, particularly large language models (LLMs), has become central to strategic decision-making. The emergence of mainstream LLMs such as OpenAI’s ChatGPT, Anthropic’s Claude, and Google’s Gemini has sparked a wave of curiosity and experimentation across industries. Decision-makers are asking whether these powerful tools can be harnessed for tasks such as formula validation, label review, and regulatory interpretation. This exploration is not merely academic; it carries significant implications for operational efficiency, risk management, and competitive advantage.
To understand the role of LLMs in product compliance, it is essential to first appreciate the nature of compliance itself. Product compliance is a multifaceted discipline that encompasses the interpretation and application of laws, regulations, and standards to ensure that products meet the requirements of the markets in which they are sold. This process involves a combination of technical expertise, legal acumen, and operational rigor. Compliance professionals must navigate a dynamic environment where regulations are frequently updated, interpretations evolve, and enforcement priorities shift. The stakes are high, as non-compliance can result in product recalls, fines, reputational damage, and even legal liability.
The promise of LLMs lies in their ability to process and generate human-like language at scale. These models are trained on vast corpora of text, enabling them to understand context, extract meaning, and generate coherent responses to a wide range of prompts. In the context of product compliance, LLMs can automate or augment tasks that have traditionally required significant manual effort. For example, they can analyze regulatory documents, summarize requirements, identify potential compliance issues in product formulations, and review product labels for adherence to prescribed formats and content.
Mainstream LLMs such as ChatGPT, Claude, and Gemini have demonstrated remarkable capabilities in natural language understanding and generation. These models can ingest regulatory texts, product specifications, and other relevant documents, and provide insights or recommendations based on their training data. For instance, an LLM can be prompted to review an ingredient list against the requirements of the European Union’s cosmetic regulations, highlighting any substances that are restricted or prohibited. Similarly, an LLM can examine a product label and assess whether it includes all mandatory elements, such as allergen statements, nutritional information, and safety warnings, as required by the U.S. Food and Drug Administration.
The practical applications of LLMs in compliance are not limited to simple checks. These models can also assist in drafting compliance checklists, generating summaries of regulatory changes, and even providing preliminary interpretations of ambiguous requirements. For example, a compliance team might use an LLM to generate a summary of recent updates to food labeling regulations in a particular jurisdiction, or to draft a checklist of requirements for a new product category. In these scenarios, LLMs can significantly reduce the time and effort required to stay abreast of regulatory developments and ensure product compliance.
Despite these promising capabilities, it is important to recognize the inherent limitations and risks associated with using LLMs for compliance tasks. One of the primary challenges is the generalist nature of mainstream LLMs. While these models are trained on a broad range of texts, they lack the deep domain expertise needed to interpret complex or nuanced regulatory requirements. Compliance is a field where context matters immensely, and where the interpretation of a single word or phrase can have significant implications. LLMs may lack the specialized knowledge needed to accurately assess compliance in edge cases or to interpret evolving regulatory guidance.
Another significant limitation is the phenomenon of hallucinations, where LLMs generate information that is plausible but incorrect. This risk is particularly acute in compliance, where decisions must be based on accurate and verifiable information. An LLM might, for example, incorrectly assert that a particular ingredient is permitted in a certain jurisdiction, or misinterpret the formatting requirements for a product label. Such errors can have serious consequences, including regulatory enforcement actions and product recalls.
The static nature of out-of-the-box LLMs also poses challenges. These models are trained on data available up to a specific point in time and do not receive real-time updates unless specifically integrated with external data sources. In the fast-moving world of regulatory compliance, where new guidance and enforcement actions are issued regularly, this limitation can result in outdated or incomplete recommendations.
Traceability is another critical compliance requirement that is not inherently supported by mainstream LLMs. Compliance decisions must be documented and auditable, with a clear record of the rationale and sources used. By default, LLMs do not provide an audit trail of their reasoning or the data sources they rely on. This lack of transparency can undermine confidence in their outputs and create challenges in the event of regulatory scrutiny.
To maximize the value of LLMs in compliance, it is essential to adopt best practices in prompt and context engineering. The quality and specificity of prompts directly affect the relevance and accuracy of LLM outputs. When engaging with an LLM for compliance tasks, prompts should be structured to provide clear context, define the scope of the inquiry, and specify the desired response format. For example, rather than simply asking an LLM to “review this label,” a more effective prompt would be: “Assume you are a regulatory affairs specialist. Review the following product label for compliance with FDA nutrition labeling requirements, focusing on the presence and formatting of allergen statements, serving size, and daily value percentages. Provide your findings in a table with columns for issue, regulation cited, and suggested correction.” By providing detailed context and explicit instructions, users can guide the LLM to produce more relevant and actionable outputs.
In addition to specificity, prompts should include relevant examples and reference materials whenever possible. For instance, providing the LLM with a compliant label as a benchmark can help it identify deviations in the label under review. Similarly, including excerpts from the relevant regulations can anchor the LLM’s analysis in authoritative sources. This approach not only improves the accuracy of the outputs but also enhances their traceability and defensibility.
Despite these strategies, it is crucial to acknowledge that LLMs are not a substitute for human expertise in compliance. The deployment of LLMs in production environments, particularly for high-stakes compliance decisions, carries significant risks if not supported by AI engineers and subject matter experts (SMEs). AI engineers play a vital role in integrating LLMs with internal systems, ensuring data security, and monitoring model performance. SMEs provide the domain knowledge necessary to interpret regulatory requirements, validate LLM outputs, and address edge cases that fall outside the scope of the model’s training.
Come in, let me show you some of the magic
To give a peek into how Signify harnesses the power of LLMs in the regulatory and compliance domain layer, let's look at some of the first principles of our architecture, starting with a technique called
Contextual Retrieval
Most AI systems that work with large document repositories rely on a method called Retrieval-Augmented Generation (RAG). In standard RAG, documents are broken into smaller "chunks" of text, converted into mathematical representations called embeddings, and stored in a database. When you ask a question, the system searches for chunks that seem semantically related to your query and feeds them to the language model to generate an answer.
The problem? Traditional RAG solutions remove context when encoding information, often leading the system to fail to retrieve relevant information from the knowledge base. [anthropic]
Consider a practical compliance scenario. You're researching labeling requirements, and your system retrieves a chunk that states: "The product must display warnings in a font size no smaller than the largest text on the principal display panel." Useful information—but which regulation is this from? Is it FDA food labeling under 21 CFR 101? Cosmetic labeling under the Fair Packaging and Labeling Act? A state-level requirement like California's Proposition 65? Without that context, the information is ambiguous at best and potentially dangerous at worst if applied to the wrong product category or jurisdiction.
This is what Anthropic's engineering team calls "the context conundrum." When documents are split into smaller pieces for efficient processing, individual chunks lack sufficient context [anthropic] to be reliably retrieved or correctly interpreted. In regulatory work, where the difference between FDA guidance and binding regulation—or between EU and US requirements—can determine whether a product launch succeeds or results in a warning letter, this context loss is unacceptable.
How Contextual Retrieval Works
Contextual Retrieval solves this problem by prepending explanatory context to each chunk before it enters the system. Rather than storing a decontextualized fragment, the system first uses an LLM to analyze where that chunk sits within the broader document and generates a brief contextual header.
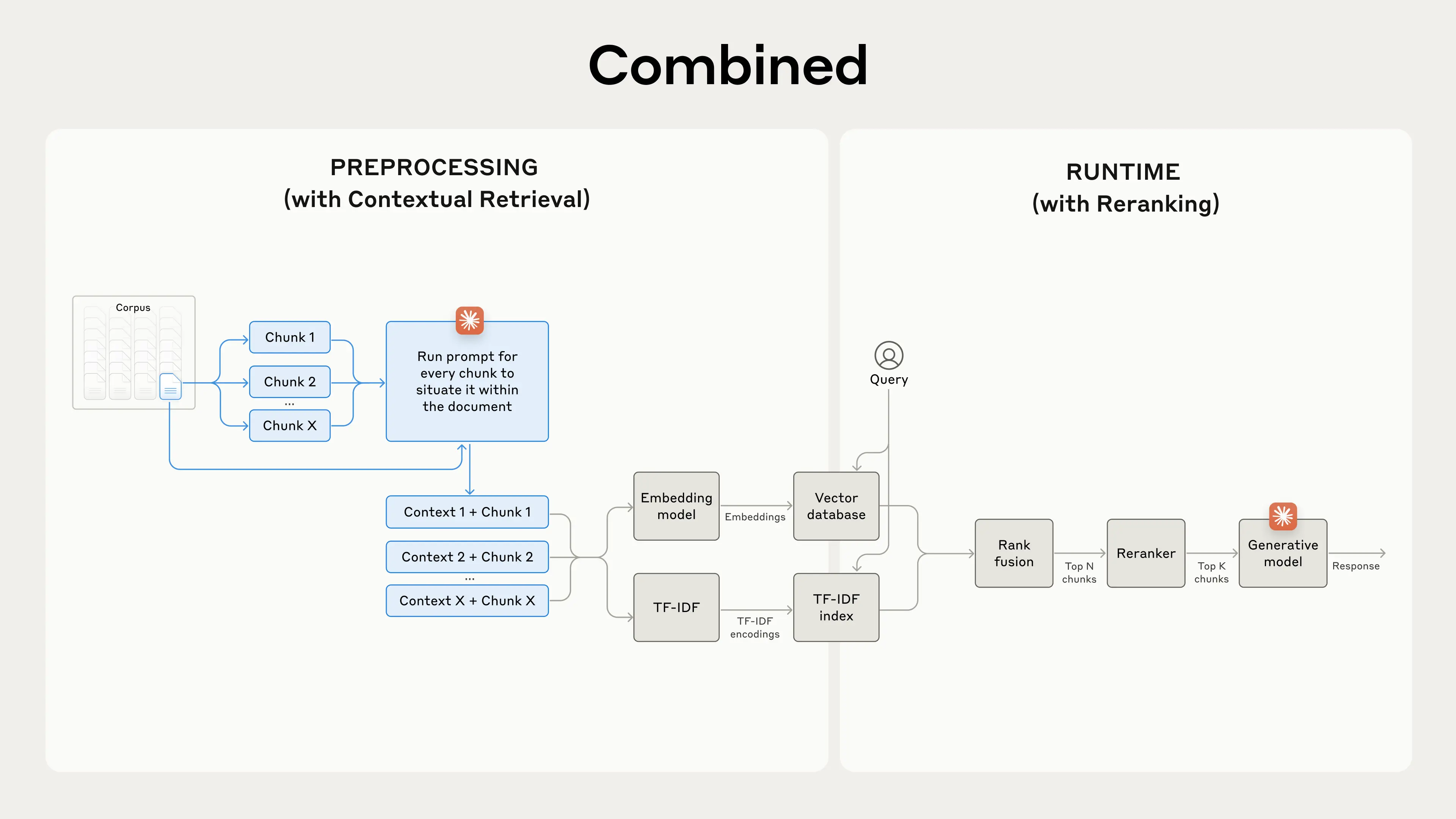
[Image credit: Anthropic]
For example, a raw chunk reading "The company's revenue grew by 3% over the previous quarter" would be transformed into: "This chunk is from an SEC filing on ACME Corp's performance in Q2 2023; the previous quarter's revenue was $314 million. The company's revenue grew by 3% over the previous quarter."
In the regulatory domain, this same principle transforms how compliance documents are processed. A chunk containing "colorants must be listed in descending order of predominance" gets prepended with context identifying it as originating from EU Regulation 1223/2009, Article 19, paragraph 1(g), governing cosmetic product labeling within the European Union market. Now, when a compliance professional asks about ingredient listing requirements, the system can accurately distinguish between EU cosmetic regulations, US FDA requirements under 21 CFR 701.3, and other jurisdictional frameworks.
The technical implementation combines two retrieval methods: semantic embeddings (which find conceptually related content) and BM25 lexical matching (which finds exact terminology matches). This dual approach is particularly valuable in compliance work, where queries often include precise regulatory citations such as "21 CFR 101.22(i)" or specific terms of art such as "Generally Recognized as Safe" that require exact matching rather than semantic interpretation.
Anthropic's testing demonstrated that combining Contextual Embeddings and Contextual BM25 reduced the top-20-chunk retrieval failure rate by 49% [anthropic]. When combined with an additional reranking step that scores retrieved chunks for relevance, the top-20-chunk retrieval failure rate dropped by 67% [anthropic].
In the case of Signify, we've calibrated these retrieval systems with a specific asymmetry in mind: in regulatory and compliance workflows, the cost of missing a relevant chunk (a false negative) is almost always higher than the cost of surfacing an irrelevant one. If a system fails to retrieve an applicable FDA warning requirement or an EU restriction on a specific ingredient, the downstream consequences—non-compliant labeling, rejected market applications, or regulatory enforcement—far outweigh the minor inefficiency of a compliance professional reviewing an extra paragraph of tangentially related guidance. This risk profile fundamentally shapes how we stress-test our retrieval architecture. We evaluate multiple contextual relevancy techniques—varying chunk sizes, embedding models, reranking thresholds, and hybrid retrieval weightings—to identify the technical construct that maximizes recall for the product compliance domain. The goal isn't generic "good enough" performance; it's ensuring that when a regulatory affairs manager queries the system about permissible claims for a dietary supplement, every relevant provision from 21 CFR 101.93, applicable FTC guidance, and pertinent FDA warning letters surfaces for review. We'd rather deliver comprehensive results that require human judgment to prioritize than risk a critical omission that only becomes apparent during an FDA inspection.
[Image: Signify regulatory corpus and query relevancy test results from multiple context retrieval techniques and chunking strategies.]
Why This Matters for Compliance Professionals
For regulatory affairs teams, these aren't abstract performance metrics—they translate directly into operational reliability.
When you ask an AI system whether your new beverage formulation complies with FDA labeling requirements, you need confidence that the system is retrieving the correct regulations from the correct jurisdiction, interpreting them in the correct context. A 49% reduction in retrieval failures means dramatically fewer instances of the system pulling irrelevant guidance, conflating EU and US requirements, or missing a critical provision buried in a lengthy guidance document.
In practical terms, Contextual Retrieval enables AI to function more like an experienced regulatory affairs specialist who instinctively knows that a labeling question about a probiotic supplement requires different source material than the same question about a conventional food—even when the surface-level query looks identical. The system maintains awareness of jurisdictional boundaries, document hierarchies (binding regulation versus non-binding guidance), and temporal validity (superseded versus current requirements).
For compliance leaders evaluating AI solutions, this architectural choice reflects a fundamental design philosophy: regulatory AI must be built from first principles that prioritize accuracy and traceability over speed and convenience. The cost of a wrong answer in compliance—whether measured in warning letters, product recalls, or market access delays—far exceeds the computational cost of maintaining rich contextual metadata throughout the retrieval pipeline.
Without this support, organizations risk encountering a range of challenges. Model drift, where the performance of an LLM degrades over time due to changes in data or regulatory requirements, can go undetected without proper monitoring. Integration challenges can impede the flow of information between the LLM and other compliance tools or databases, limiting the effectiveness of the solution. Most importantly, the absence of SMEs increases the likelihood of errors or omissions in compliance assessments, exposing the organization to regulatory and reputational risks.
The complexity of compliance, combined with the limitations of mainstream LLMs, has led to the emergence of specialized business applications that are purpose-built for compliance tasks. These applications leverage LLM strengths while addressing their weaknesses by integrating domain-specific knowledge, structured data, and advanced analytics. One of the foundational elements of these specialized solutions is the use of ontologies.
Ontologies are structured representations of knowledge within a particular domain. In the context of product compliance, an ontology might define the relationships between ingredients, regulatory limits, product categories, labeling requirements, and other relevant entities. By encoding this knowledge in a machine-readable format, ontologies enable compliance applications to reason about complex requirements, identify dependencies, and ensure consistency in decision-making. When combined with LLMs, ontologies provide a framework for grounding the model’s outputs in authoritative, domain-specific logic.
In specialized compliance applications, LLMs often serve as interpreters or judges rather than as primary decision makers. For example, a rule-based engine might use an ontology to determine whether a product formulation complies with relevant regulations. The LLM can then review the findings, explain the rationale, and draft communications or reports for stakeholders. This division of labor leverages the strengths of both approaches: the precision and consistency of rule-based reasoning, and the flexibility and expressiveness of natural language generation.
Advanced compliance solutions also incorporate computer vision techniques to automate the extraction and analysis of information from product labels. Computer vision algorithms can process images of labels, identify text and graphical elements, and reconstruct the layout of the label. This capability is particularly valuable for ensuring that labels meet formatting requirements, such as font size, placement of mandatory elements, and contrast ratios. By integrating computer vision with LLMs and ontologies, compliance applications can automate end-to-end label review processes, from image capture to compliance assessment and reporting.
Another critical component of modern compliance solutions is the ability to crawl the web for the latest regulatory updates and interpretations. Regulatory landscapes are constantly evolving, with new guidance, enforcement actions, and best practices emerging regularly. Web crawlers can monitor official regulatory websites, industry publications, and other authoritative sources, extracting relevant information and updating the compliance knowledge base. This ensures that compliance assessments are always based on the most current information, reducing the risk of relying on outdated or incomplete data.
The integration of these technologies creates a powerful ecosystem for product compliance. A typical workflow might begin with uploading a product label image, which is then processed by computer vision algorithms to extract text and layout information. The extracted data is then analyzed by a rule-based engine, guided by an ontology that encodes the relevant regulatory requirements. The findings are reviewed and interpreted by an LLM, which generates a detailed report highlighting any compliance issues and suggesting corrective actions. Web crawlers continuously update the knowledge base with the latest regulatory developments, ensuring that the system remains current and accurate. Throughout this process, SMEs oversee the outputs, validate the findings, and provide expert judgment where necessary.
This approach offers several advantages over relying solely on mainstream LLMs. By grounding compliance assessments in structured knowledge and real-time data, specialized applications provide greater accuracy, consistency, and traceability. The integration of computer vision and web crawling extends the solution's reach, enabling it to handle a wider range of inputs and stay abreast of regulatory changes. Most importantly, the involvement of SMEs ensures that the system remains aligned with the organization’s risk tolerance and compliance objectives.
For decision-makers, adopting LLMs for product compliance should be viewed as a journey rather than a destination. The initial excitement surrounding mainstream LLMs is understandable, given their impressive capabilities and ease of use. However, the complexity of compliance demands a more nuanced approach. Organizations should begin by identifying specific use cases where LLMs can add value, such as automating routine document reviews or generating compliance checklists. These applications can deliver quick wins and build organizational confidence in AI-driven solutions.
As organizations gain experience with LLMs, they should invest in developing specialized applications that integrate ontologies, computer vision, and web crawling. This requires collaboration among compliance professionals, AI engineers, and domain experts to design and implement solutions tailored to the organization’s unique needs. The goal should be to create a robust, scalable, and auditable compliance ecosystem that leverages the strengths of AI while mitigating its risks.
The path to effective AI-driven compliance also involves a commitment to continuous improvement. Regulatory environments are dynamic, and compliance solutions must evolve in tandem. Organizations should establish processes for monitoring model performance, updating ontologies, and incorporating new regulatory guidance. Regular training and upskilling of compliance teams are essential to ensure that they can effectively leverage AI tools and interpret their outputs.
In conclusion, the use of LLMs for product compliance offers organizations a significant opportunity to enhance efficiency, reduce risk, and accelerate time-to-market. Mainstream LLMs such as ChatGPT, Claude, and Gemini offer valuable capabilities out of the box, particularly for automating routine tasks and generating preliminary insights. However, the complexity and high stakes of compliance require a more sophisticated approach. By investing in specialized business applications that integrate ontologies, computer vision, web crawling, and human expertise, organizations can build compliance solutions that are accurate, reliable, and future-proof. The journey to AI-driven compliance is complex, but with the right strategy and investment, it offers the potential to transform the way organizations manage regulatory risk and achieve operational excellence.
The decision to leverage LLMs for compliance should be informed by a clear understanding of both the opportunities and the challenges. While LLMs can automate and augment many aspects of compliance, they are not a panacea. The integration of structured knowledge, real-time data, and expert oversight is essential to ensure that compliance solutions are both effective and defensible. As the regulatory landscape continues to evolve, organizations that embrace this holistic approach will be well-positioned to navigate complexity, seize new opportunities, and maintain the trust of regulators, customers, and stakeholders.
The journey begins with a single step: a commitment to exploring the potential of LLMs, investing in the necessary expertise, and building the foundations for a new era of AI-driven compliance. By doing so, organizations can not only meet the challenges of today’s regulatory environment but also unlock new possibilities for innovation and growth in the years to come.
Jan 22, 2026